If you've been using EC2 for anything serious then you have some code on your instances that requires your AWS credentials. I'm talking about code that does things like this:
- Attach an EBS volume (requires your X.509 certificate and private key)
- Download your application from a non-public location in S3 (requires your secret access key)
- Send and receive SQS messages (requires your secret access key)
- Query or update SimpleDB (requires your secret access key)
How do you get the credentials onto the instance in the first place? How can you store them securely once they're there? First let's examine the issues involved in securing your keys, and then we'll explore the available options for doing so.
Potential Vulnerabilities in Transferring and Storing Your CredentialsThere are a number of vulnerabilities that should be considered when trying to protect a secret. I'm going to ignore the ones that result from obviously foolish practice, such as transferring secrets unencrypted.
- Root: root can get at any file on an instance and can see into any process's memory. If an attacker gains root access to your instance, and your instance can somehow know the secret, your secret is as good as compromised.
- Privilege escalation: User accounts can exploit vulnerabilities in installed applications or in the kernel (whose latest privilege escalation vulnerability was patched in new Amazon Kernel Images on 28 August 2009) to gain root access.
- User-data: Any user account able to open a socket on an EC2 instance can see the user-data by getting the URL
http://169.254.169.254/latest/user-data . This is exploitable if a web application running in EC2 does not validate input before visiting a user-supplied URL. Accessing the user-data URL is particularly problematic if you use the user-data to pass in the secret unencrypted into the instance - one quick wget (or curl) command by any user and your secret is compromised. And, there is no way to clear the user-data - once it is set at launch time, it is visible for the entire life of the instance. - Repeatability: HTTPS URLs transport their content securely, but anyone who has the URL can get the content. In other words, there is no authentication on HTTPS URLs. If you specify an HTTPS URL pointing to your secret it is safe in transit but not safe from anyone who discovers the URL.
Benefits Offered by Transfer and Storage Methods
Each transfer and storage method offers a different set of benefits. Here are the benefits against which I evaluate the various methods presented below:
- Easy to do. It's easy to create a file in an AMI, or in S3. It's slightly more complicated to encrypt it. But, you should have a script to automate the provision of new credentials, so all of the methods are graded as "easy to do".
- Possible to change (now). Once an instance has launched, can the credentials it uses be changed?
- Possible to change (future). Is it possible to change the credentials that will be used by instances launched in the future? All methods provide this benefit but some make it more difficult to achieve than others, for example instances launched via Auto Scaling may require the Launch Configuration to be updated.
How to Put AWS Credentials on an EC2 InstanceWith the above vulnerabilities and benefits in mind let's look at different ways of getting your credentials onto the instance and the consequences of each approach.
Mitch Garnaat has a great set of articles about the AWS credentials.
Part 1 explores what each credential is used for, and
part 2 presents some methods of getting them onto an instance, the risks involved in leaving them there, and a strategy to mitigate the risk of them being compromised. A summary of part 1: keep all your credentials secret, like you keep your bank account info secret, because they are - literally - the keys to your AWS kingdom.
As discussed in part 2 of Mitch's article, there are a number of methods to get the credentials (or indeed, any secret) onto an instance:
1. Burn the secret into the AMIPros:
Cons:
- Not possible to change (now) easily. Requires SSHing into the instance, updating the secret, and forcing all applications to re-read it.
- Not possible to change (future) easily. Requires bundling a new AMI.
- The secret can be mistakenly bundled into the image when making derived AMIs.
Vulnerabilities:
- root, privilege escalation.
2. Pass the secret in the user-dataPros:
- Easy to do. Putting the secret into the user-data must be integrated into the launch procedure.
- Possible to change (future). Simply launch new instances with updated user-data. With Auto Scaling, create a new Launch Configuration with the updated user-data.
Cons:
- Not possible to change (now). User-data cannot be changed once an instance is launched.
Vulnerabilities:
- user-data, root, privilege escalation.
Here are some additional methods to transfer a secret to an instance, not mentioned in the article:
3. Put the secret in a public URL
The URL can be on a website you control or in S3. It's insecure and foolish to keep secrets in a publicly accessible URL. Please don't do this, I had to mention it just to be comprehensive.
Pros:
- Easy to do.
- Possible to change (now). Simply update the content at that URL. Any processes on the instance that read the secret each time will see the new value once it is updated.
- Possible to change (future).
Cons:
- Completely insecure. Any attacker between the endpoint and the EC2 boundary can see the packets and discover the URL, revealing the secret.
Vulnerabilities:
- repeatability, root, privilege escalation.
4. Put the secret in a private S3 object and provide the object's path
To get content from a private S3 object you need the secret access key in order to authenticate with S3. The question then becomes "how to put the secret access key on the instance", which you need to do via one of the other methods.
Pros:
- Easy to do.
- Possible to change (now). Simply update the content at that URL. Any processes on the instance that read the secret each time will see the new value once it is updated.
- Possible to change (future).
Cons:
- Inherits the cons of the method used to transfer the secret access key.
Vulnerabilities:
- root, privilege escalation.
5. Put the secret in a private S3 object and provide a signed HTTPS S3 URLThe signed URL must be created before launching the instance and specified somewhere that the instance can access - typically in the user-data. The signed URL expires after some time, limiting the window of opportunity for an attacker to access the URL. The URL should be HTTPS so that the secret cannot be sniffed in transit.
Pros:
- Easy to do. The S3 URL signing must be integrated into the launch procedure.
- Possible to change (now). Simply update the content at that URL. Any processes on the instance that read the secret each time will see the new value once it is updated.
- Possible to change (future). In order to integrate with Auto Scaling you would need to (automatically) update the Auto Scaling Group's Launch Configuration to provide an updated signed URL for the user-data before the previously specified signed URL expires.
Cons:
- The secret must be cached on the instance. Once the signed URL expires the secret cannot be fetched from S3 anymore, so it must be stored on the instance somewhere. This may make the secret liable to be burned into derived AMIs.
Vulnerabilities:
- repeatability (until the signed URL expires), root, privilege escalation.
6. Put the secret on the instance from an outside source, via SCP or SSHThis method involves an outside client - perhaps your local computer, or a management node - whose job it is to put the secret onto the newly-launched instance. The management node must have the private key with which the instance was launched, and must know the secret in order to transfer it. This approach can also be automated, by having a process on the management node poll every minute or so for newly-launched instances.
Pros:
- Easy to do. OK, not "easy" because it requires an outside management node, but it's doable.
- Possible to change (now). Have the management node put the updated secret onto the instance.
- Possible to change (future). Simply put a new secret onto the management node.
Cons:
- The secret must be cached somewhere on the instance because it cannot be "pulled" from the management node when needed. This may make the secret liable to be burned into derived AMIs.
Vulnerabilities:
- root, privilege escalation.
The above methods can be used to transfer the credentials - or any secret - to an EC2 instance.
Instead of transferring the secret directly, you can transfer an encrypted secret. In that case, you'd need to provide a decryption key also - and you'd use one of the above methods to do that. The overall security of the secret would be influenced by the combination of methods used to transfer the encrypted secret and the decryption key. For example, if you encrypt the secret and pass it in the user-data, providing the decryption key in a file burned into the AMI, the secret is vulnerable to anyone with access to both user-data and the file containing the decryption key. Also, if you encrypt your credentials then changing the encryption key requires changing two items: the encryption key and the encrypted credentials. Therefore, changing the encryption key can only be as easy as changing the credentials themselves.
How to Keep AWS Credentials on an EC2 InstanceOnce your credentials are on the instance, how do you keep them there securely?
First off, let's remember that in an environment out of your control, such as EC2, you have no guarantees of security. Anything processed by the CPU or put into memory is vulnerable to bugs in the hypervisor (the virtualization provider) or to malicious AWS personnel (though the
AWS Security White Paper goes to great lengths to explain the internal procedures and controls they have implemented to mitigate that possibility) or to legal search and seizure. What this means is that you should only run applications in EC2 for which the risk of secrets being exposed via these vulnerabilities is acceptable. This is true of all applications and data that you allow to leave your premises. But this article is about the security of the AWS credentials, which control the access to your AWS resources. It is perfectly acceptable to ignore the risk of abuse by AWS personnel exposing your credentials because AWS folks can manipulate your account resources without needing your credentials! In short, if you are willing to use AWS then you trust Amazon with your credentials.
There are three ways to store information on a running machine: on disk, in memory, and not at all.
1. Keeping a secret on diskThe secret is stored in a file on disk, with the appropriate permissions set on the file. The secret survives a reboot intact, which can be a pro or a con: it's a good thing if you want the instance to be able to remain in service through a reboot; it's a bad thing if you're trying to hide the location of the secret from an attacker, because the reboot process contains the script to retrieve and cache the secret, revealing its cached location. You can work around this by altering the script that retrieves the secret, after it does its work, to remove traces of the secret's location. But applications will still need to access the secret somehow, so it remains vulnerable.
Pros:
- Easily accessible by applications on the instance.
Cons:
- Visible to any process with the proper permissions.
- Easy to forget when bundling an AMI of the instance.
Vulnerabilities:
- root, privilege escalation.
2. Keeping the secret in memoryThe secret is stored as a file on a ramdisk. (There are other memory-based methods, too.) The main difference between storing the secret in memory and on the filesystem is that memory does not survive a reboot. If you remove the traces of retrieving the secret and storing it from the startup scripts after they run during the first boot, the secret will only exist in memory. This can make it more difficult for an attacker to discover the secret, but it does not add any additional security.
Pros:
- Easily accessible by applications on the instance.
Cons:
- Visible to any process with the proper permissions.
Vulnerabilities:
- root, privilege escalation.
3. Do not store the secret; retrieve it each time it is neededThis method requires your applications to support the chosen transfer method.
Pros:
- Secret is never stored on the instance.
Cons:
- Requires more time because the secret must be fetched each time it is needed.
- Cannot be used with signed S3 URLs. These URLs expire after some time and the secret will no longer be accessible. If the URL does not expire in a reasonable amount of time then it is as insecure as a public URL.
- Cannot be used with externally-transferred (via SSH or SCP) secrets because the secret cannot be pulled from the management node. Any protocol that tries to pull the secret from the management node can be also be used by an attacker to request the secret.
Vulnerabilities:
- root, privilege escalation.
Choosing a Method to Transfer and Store Your CredentialsThe above two sections explore some options for transferring and storing a secret on an EC2 instance. If the secret is guarded by another key - such as an encryption key or an S3 secret access key - then this key must also be kept secret and transferred and stored using one of those same methods. Let's put all this together into some tables presenting the viable options.
Unencrypted CredentialsHere is a summary table evaluating the transfer and storage of unencrypted credentials using different combinations of methods:
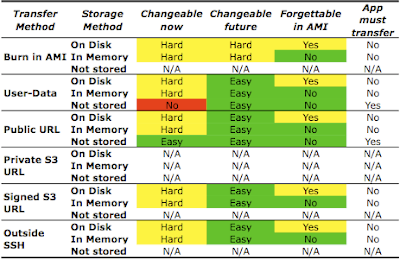
Some notes on the above table:
- Methods making it "hard" to change credentials are highlighted in yellow because, through scripting, the difficulty can be minimized. Similarly, the risk of forgetting credentials in an AMI can be minimized by scripting the AMI creation process and choosing a location for the credential file that is excluded from the AMI by the script.
- While you can transfer credentials using a private S3 URL, you still need to provide the secret access key in order to access that private S3 URL. This secret access key must also be transferred and stored on the instance, so the private S3 URL is not by itself usable. See below for an analysis of using a private S3 URL to transfer credentials. Therefore the Private S3 URL entries are marked as N/A.
- You can burn credentials into an AMI and store them in memory. The startup process can remove them from the filesystem and place them in memory. The startup process should then remove all traces from the startup scripts mentioning the key's location in memory, in order to make discovery more difficult for an attacker with access to the startup scripts.
- Credentials burned into the AMI cannot be "not stored". They can be erased from the filesystem, but must be stored somewhere in order to be usable by applications. Therefore these entries are marked as N/A.
- Credentials transferred via a signed S3 URL cannot be "not stored" because the URL expires and, once that happens, is no longer able to provide the credentials. Thus, these entries are marked N/A.
- Credentials "pushed" onto the instance from an outside source, such as SSH, cannot be "not stored" because they must be accessible to applications on the instance. These entries are marked N/A.
A glance at the above table shows that it is, overall, not difficult to manage unencrypted credentials via any of the methods. Remember: don't use the Public URL method, it's completely unsecure.
Bottom line: If you don't care about keeping your credentials encrypted then pass a signed S3 HTTPS URL in the user-data. The startup scripts of the instance should retrieve the credentials from this URL and store them in a file with appropriate permissions (or in a ramdisk if you don't want them to remain through a reboot), then the startup scripts should remove their own commands for getting and storing the credentials. Applications should read the credentials from the file (or directly from the signed URL is you don't care that it will stop working after it expires).
Encrypted CredentialsWe discussed 6 different ways of transferring credentials and 3 different ways of storing them. A transfer method and a storage method must be used for the encrypted credentials and for the decryption key. That gives us 36 combinations of transfer methods, and 9 combinations of storage methods, for a grand total of 324 choices.
Here are the first 54, summarizing the options when you choose to burn the encrypted credentials into the AMI:
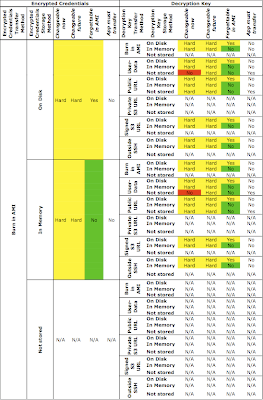
As (I hope!) you can see, all combinations that involve burning encrypted credentials into the AMI make it hard (or impossible) to change the credentials or the encryption key, both on running instances and for future ones.
Here are the next set, summarizing the options when you choose to pass encrypted credentials via the user-data:
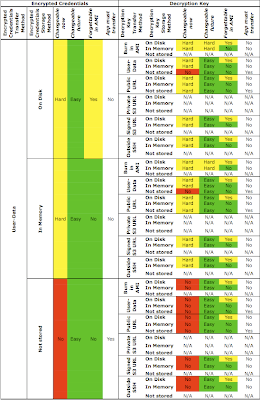
Passing encrypted credentials in the user-data requires the decryption key to be transferred also. It's pointless from a security perspective to pass the decryption key together with the encrypted credentials in the user-data. The most flexible option in the above table is to pass the decryption key via a signed S3 HTTPS URL (specified in the user-data, or specified at a public URL burned into the AMI) with a relatively short expiry time (say, 4 minutes) allowing enough time for the instance to boot and retrieve it.
Here is a summary of the combinations when the encrypted credentials are passed via a public URL:
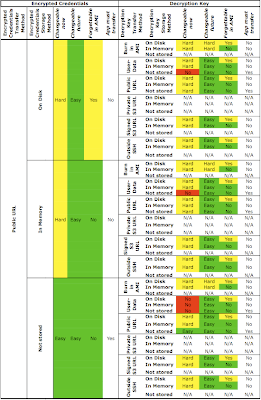
It might be surprising, but passing encrypted credentials via a public URL is actually a viable option. You just need to make sure you send and store the decryption key securely, so send that key via a signed S3 HTTPS URL (specified in the user-data on specified at a public URL burned into the AMI) for maximum flexibility.
The combinations with passing the encrypted credentials via a private S3 URL are summarized in this table:
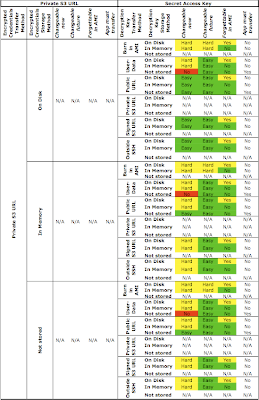
As explained earlier, the private S3 URL is not usable by itself because it requires the AWS secret access key. (The access key id is not a secret). The secret access key can be transferred and stored using the combinations of methods shown in the above table.
The most flexible of the options shown in the above table is to pass in the secret access key inside a signed S3 HTTPS URL (which is itself provided in the user-data or at a public URL burned into the AMI).
Almost there.... This next table summarizes the combinations with encrypted credentials passed via a signed S3 HTTPS URL:
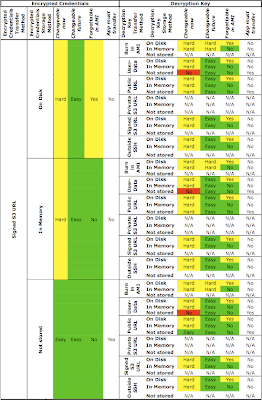
The signed S3 HTTPS URL containing the encrypted credentials can be specified in the user-data or specified behind a public URL which is burned into the AMI. The best options for providing the decryption key are via another signed URL or from an external management node via SSH or SCP.
And, the final section of the table summarizing the combinations of using encrypted credentials passed in via SSH or SCP from an outside management node:
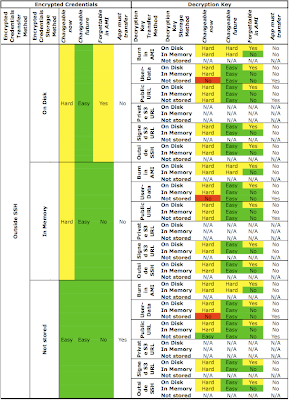
The above table summarizing the use of an external management node to place encrypted credentials on the instance shows the same exact results as the previous table (for a signed S3 HTTPS URL). The same flexibility is achieved using either method.
The Bottom LineHere's a practical recommendation: if you have code that generates signed S3 HTTPS URLs then pass in two signed URLs into the user-data, one containing the encrypted credentials and the other containing the decryption key. The startup sequence of the AMI should read these two items from their URLs, decrypt the credentials, and store the credentials in a ramdisk file with the minimum permissions necessary to run the applications. The start scripts should then remove all traces of the procedure (beginning with "read the user-data URL" and ending with "remove all traces of the procedure") from themselves.
If you don't have code to generate signed S3 URLs then burn the encrypted credentials into the AMI and pass the decryption key via the user-data. As above, the startup sequence should decrypt the credentials, store them in a ramdisk, and destroy all traces of the raw ingredients and the process itself.
This article is an informal review of the benefits and vulnerabilities offered by different methods of transferring credentials to and storing credentials on an EC2 instance. In a future article I will present scripts to automate the procedures described. In the meantime, please leave your feedback in the comments.


















